起
摸鱼时偶然刷到一个 RAID(独立磁盘冗余阵列)的视频,里面演示了 RAID1 坏掉一块硬盘后数据依然可用,突然灵光一闪——
我们最近搭的游戏服务器,几乎没有任何冗余方案。能不能也搞一套架构,让主节点彻底挂掉之后,服务还能继续跑?
说干就干,跟 DeepSeek 聊了聊技术细节,开始琢磨高可用架构。
承
现有环境: 阿里云(北京 / 杭州)两台 + 本地高性能服务器一台(无公网)。
方案一:双热备
两台本地服务器互为备份,一台挂掉另一台自动顶上。思路很美,现实很骨感——现在内存硬盘涨疯了,根本买不起第二台,Pass。
方案二:主备入口 + 本地主服务 + 云上备份
主节点故障时,由两台阿里云服务器接管全部业务。方向没问题,但主业务体量太大,那两台阿里云根本拉不动,Pass。
方案三:阿里云临时高性能节点
主节点挂掉时,在阿里云按量付费开一台临时高性能 ECS,切过去顶上。数据通过 OSS 存储桶同步,也可以用 sync 同步到杭州节点。
查了一下价格:32vCPU | 64GiB,¥6.197/时,临时流量 0.8 元/GB。作为应急方案技术上可行,但流量是大头,费用不太能接受。主打一个能省则省,Pass。
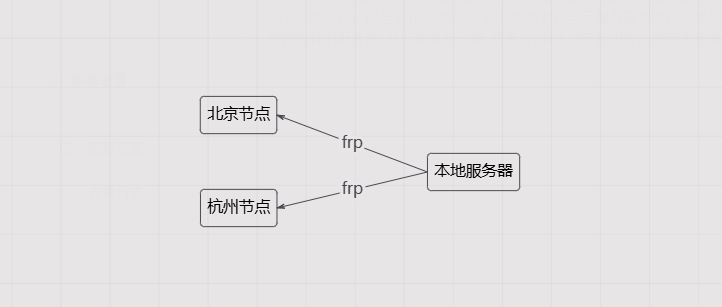
现有的冗余方案是一台主节点 + 两台互备的 Frp 节点,架构如下图:
三个方案全被否了。那到底该怎么搞——既要省钱,又要高性能?
转
在讨论 DNS 如何自动解析到临时节点 IP 的时候,突然蹦出一个想法:为什么要动 DNS?
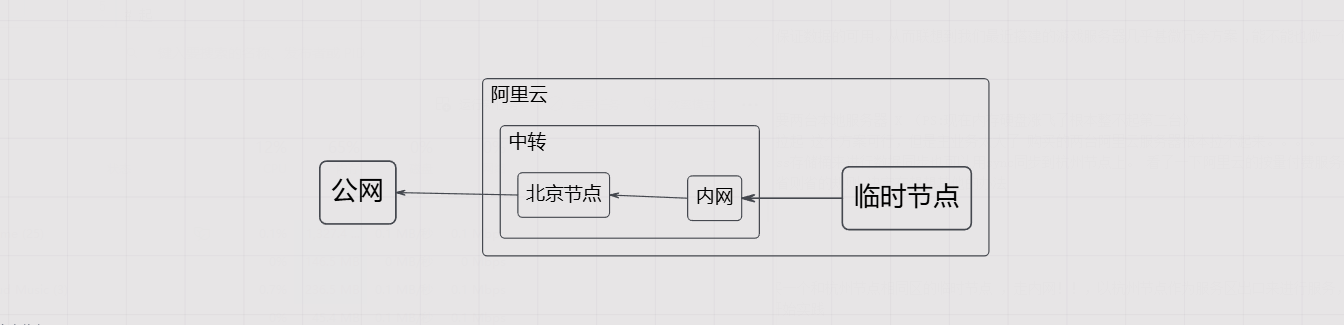
换个思路——在阿里云开一台和杭州节点同区的临时 ECS,直接走内网,以杭州节点作为出口对外提供服务。这样既不用购买公网流量,还能复用杭州节点的 200Mbps 带宽。万一杭州节点也挂了,再临时开通流量兜底。
理论可行,开干。架构如下图:
先拿北京节点跑一遍验证:
新建同区 ECS → 配置内网互通 → 部署 Frp → 访问测试
实践成功!!!
终
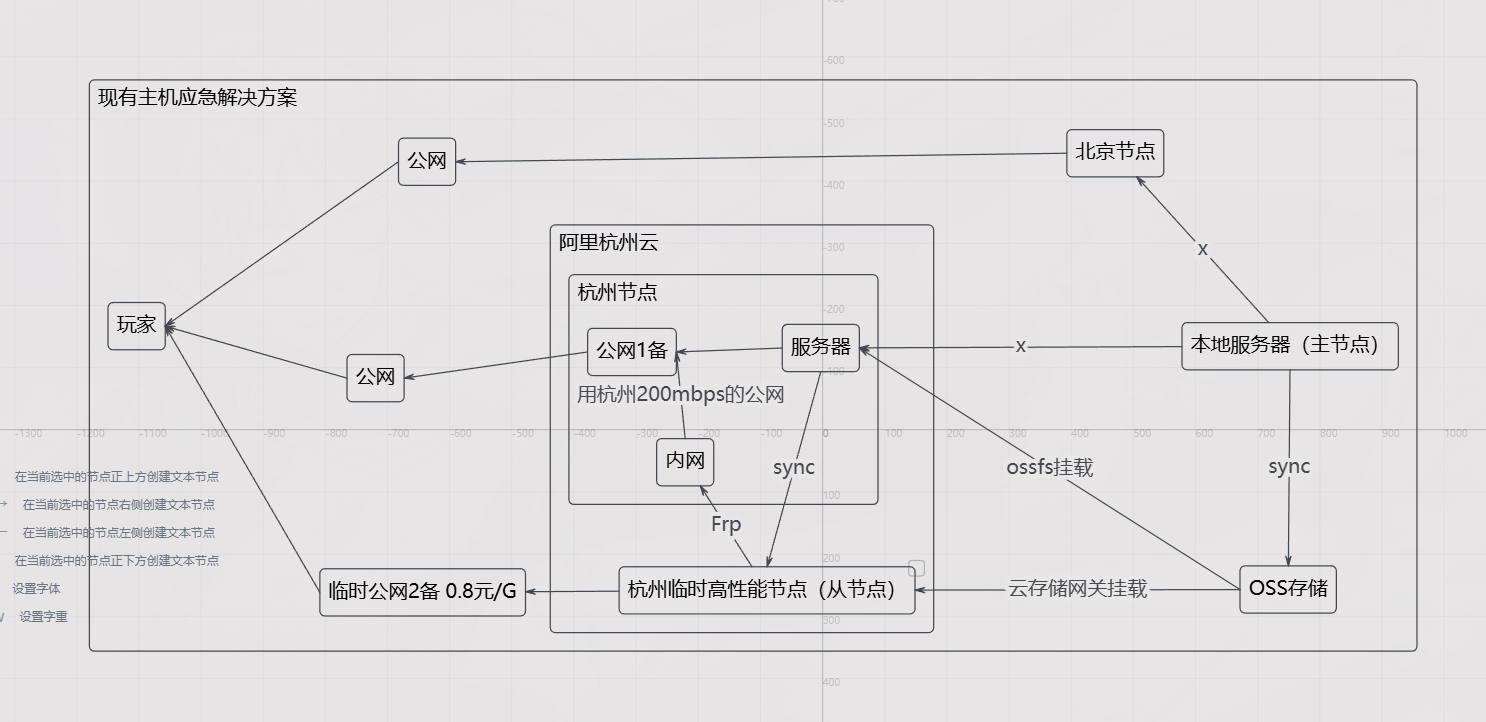
这张图画了很久,但目前只是一个大致的框架。实际落地还需要考虑数据库同步、Bot 程序、自动化部署脚本等很多方面。
写到这里突然想到:能不能通过 Docker 拉取镜像,一键部署整套数据和服务?
要是真能跑起来,那就又是一个值得记录的故事了。
本文由 zentx 编写,经 Claude Code 润色优化。